Problems in GenerativeAI: Continuity
By mrkiouak@gmail.com on 2025-05-19

Continuity across GenAI over time
This was a sort of interesting problem I realized I'd need to solve for, the scope of which had not been obvious to me when I started hacking on the experiment.
I'm working on a basic "Choose your own adventure" \ "Collaborative Storytelling" interaction (you can find it on this site at /experiments/campfire -- campfire was chosen because it evokes the kind of back and forth imaginative exchange I was targeting).
Here's a sample set of prompt interactions, and the screens generated:
Notice the details of each of the characters:
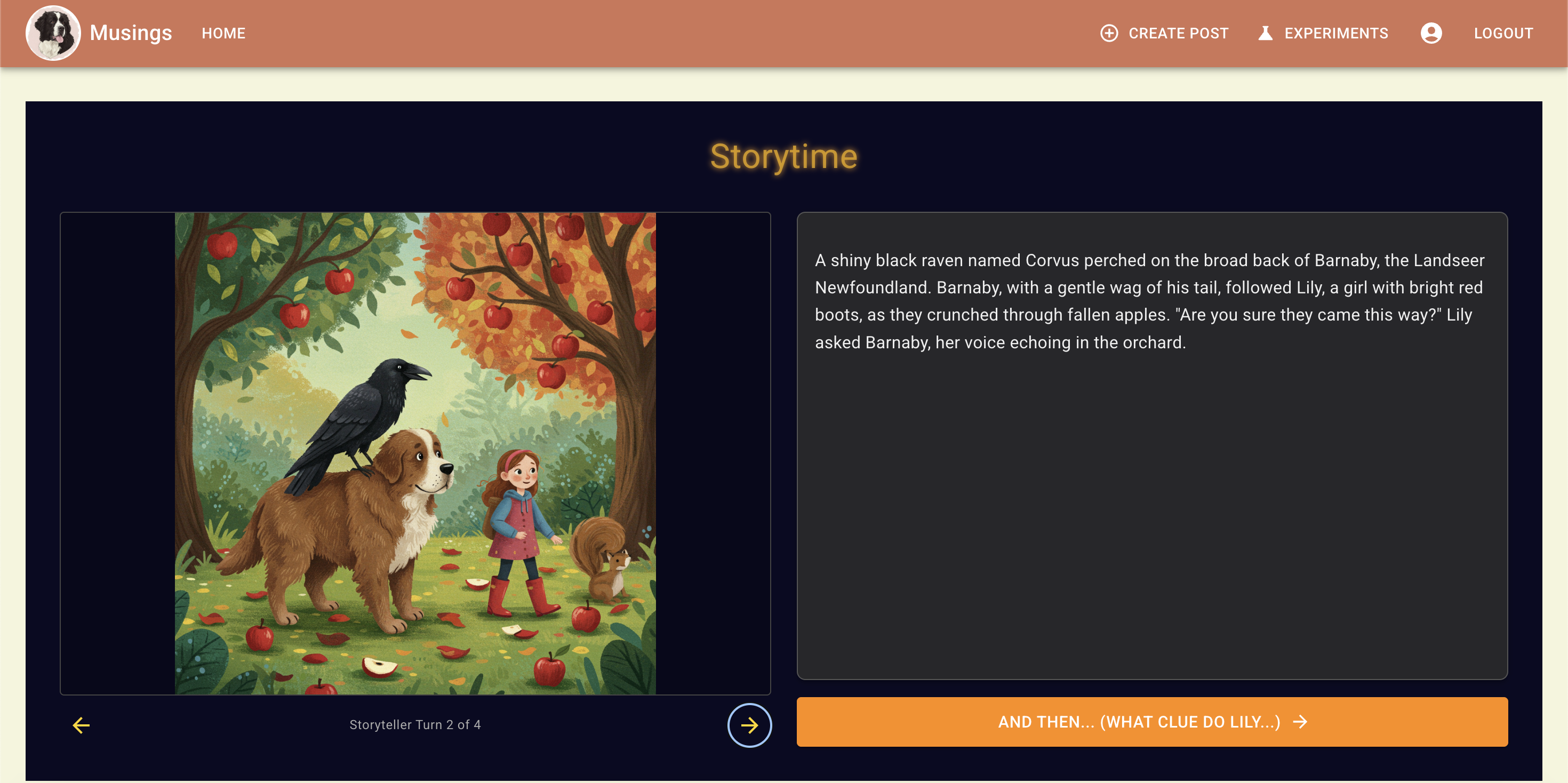
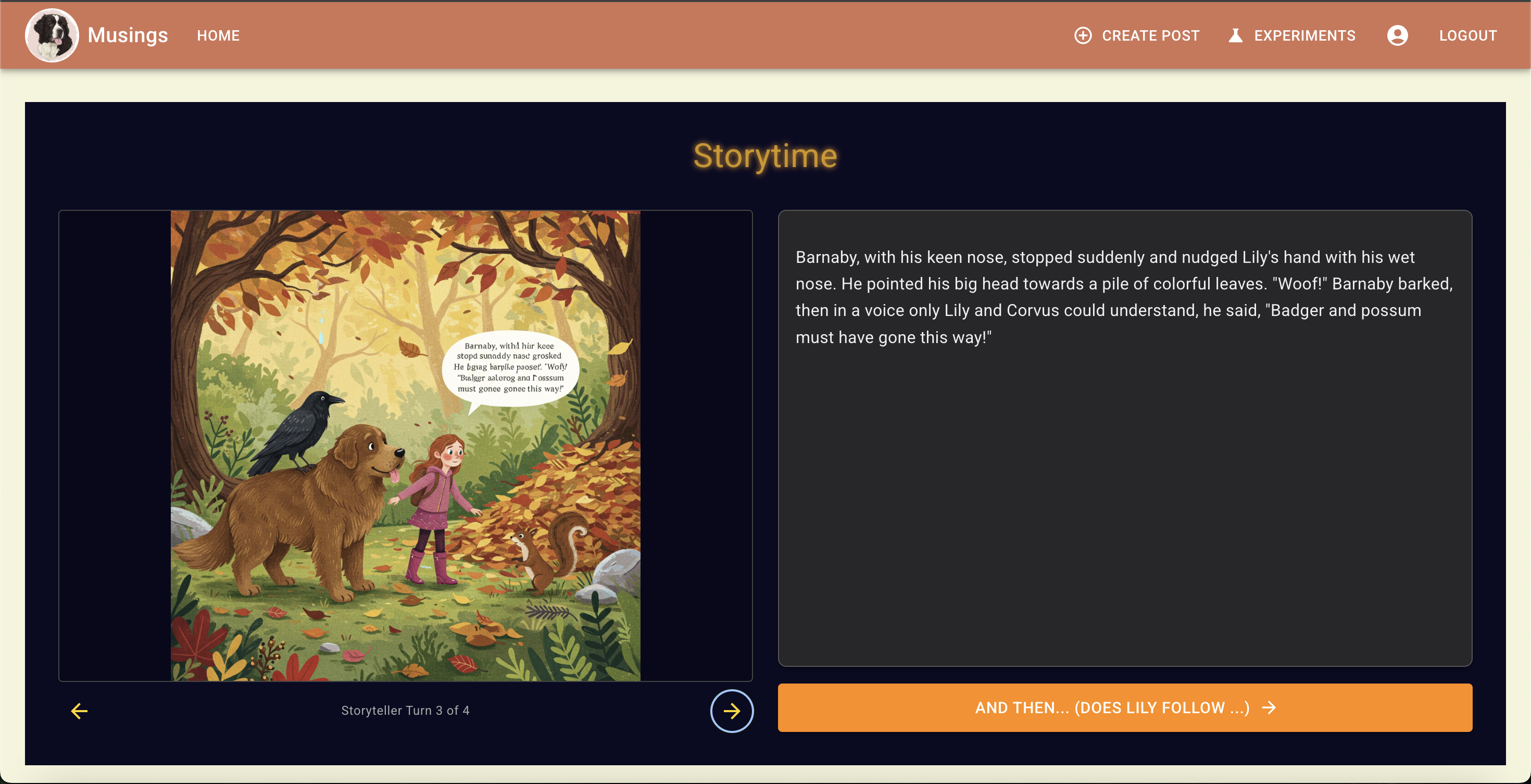
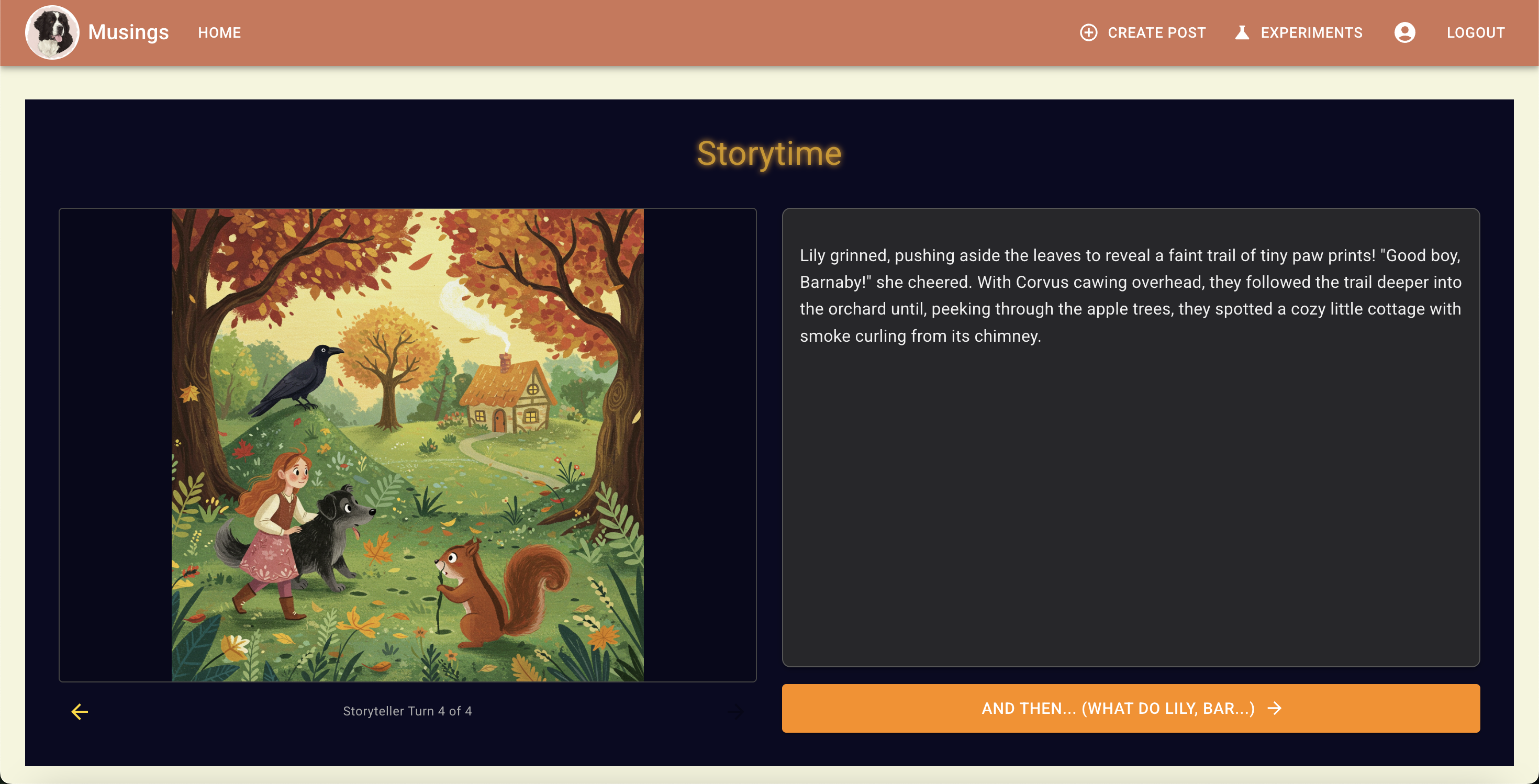
Each of these images was generated with the previous output text from the model. In this chat log,
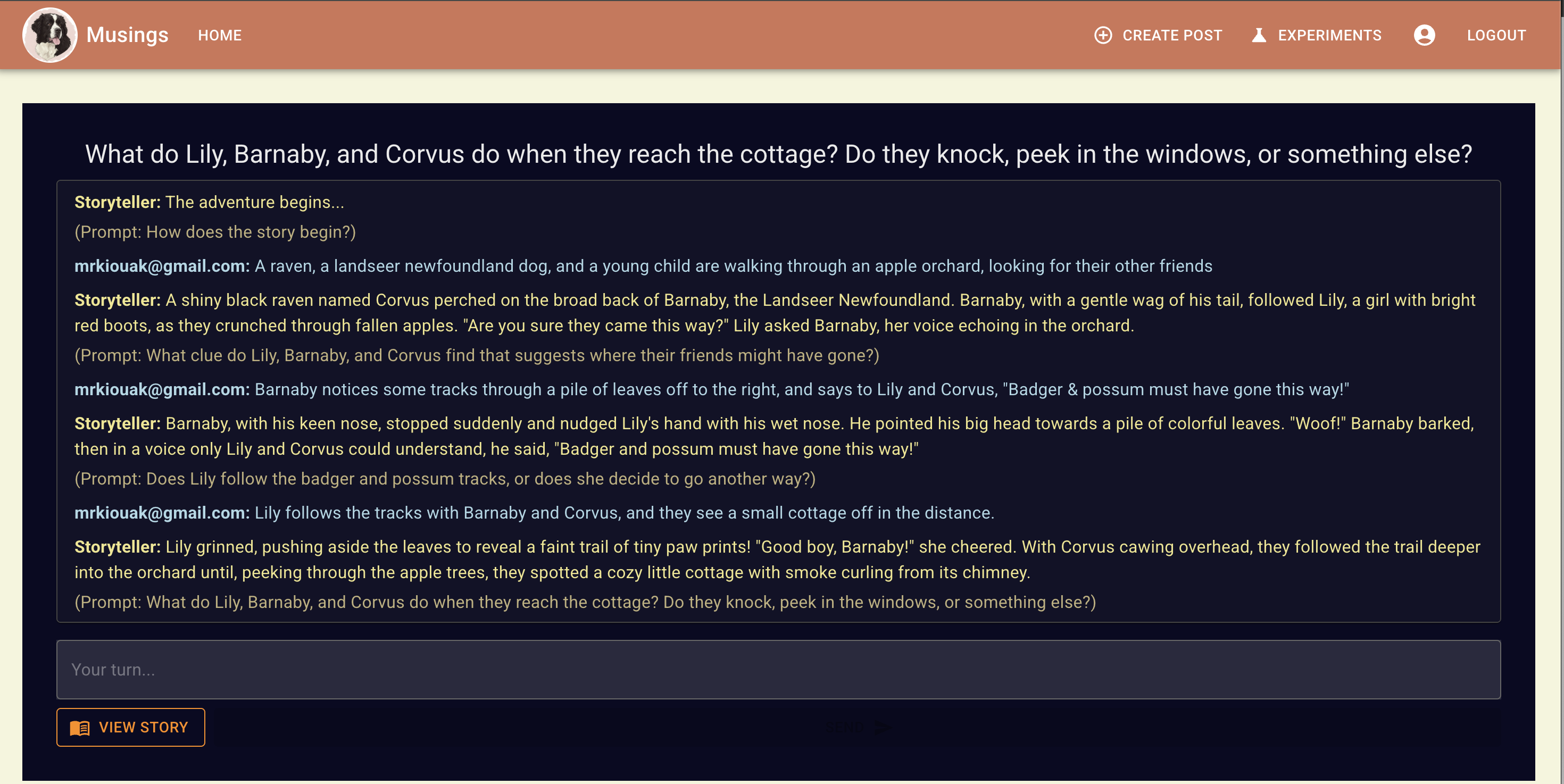
mrkiouak@gmail.com is my inputs that are sent to Gemini 2.5 Flash to generate its story text, and then it's story text is sent to imagen where imagen is prompted to generate an image corresponding to this text. In addition, the previous story text generated for other scenes (if there are previous scenes) is also sent, and the model is told to remain consistent with the details in the story.
e.g.
Imagen receives this prompt:
imagen_prompt = (
f"Illustrate the following scene from a children's fairy tale or myth: \"{current_story_segment}\"\n\n"
f"CONTEXT from the story so far: \"{full_story_context}\"\n\n"
f"The image should be in a whimsical, vibrant, and engaging style suitable for a children's storybook. "
f"Focus on the characters, actions, and atmosphere described in the LATEST scene. "
f"Ensure visual consistency with the described context if possible (e.g., character appearance, setting details mentioned previously)."
f"If specific characters were described (e.g. 'a squirrel named Squeaky with a blue-striped tail'), try to incorporate those details."
)
So from the scenes above, we can see that the dog changes color in the final scene. There are visual differences between the other characters, but none so dramatic as the dog changing from light brown to black.
This is interesting because, if you refer to my prompts in the chat log, I specifically prompted Landseer Newfoundland, and this description was repeated in the output story text from Gemini 2.5 Flash.
One other visual change is Lily's red boots -- Gemini introduced this detail in its first response, and Imagen respected it in its first image, but the boot was less red and bright in the 2nd image, and basically brown by the final -- maybe we can explain this as the boots getting muddy :), but it seems more likely Imagen isn't great at identifying salient details about named entities to prioritize in early parts of prompts.
I referenced the Ship of Theseus Thought Experiment because this GenAI problem is a bit like the reverse of the identity problem. Rather than how does the ship preserve its identity, the question is "How do you identify and collect just the right materials to be able to reconstruct the ship of Theseus on demand?" And how exact does the reproduction actually have to be?
It looks like there is a GA feature that requires approval to use that would probably solve this problem, but maybe not for multiple subjects?
And I assume the theory is some future Foundational Model will be intelligent enough to understand this and manage subject details -- but think about how much data it would need to be keeping consistent -- its hard with images, but not so hard to talk about colors. What about a generative entertainment use case where you want to describe personality and motivating beliefs, as well as colors -- and you want an image that includes body posture conveying emotion based on the personality and beliefs, as well as the right uniforms.
This should work at some future point, and I think the success of LLMs in generating realistic voices with affect and appropriate pacing & intonation to convey emotions suggests this is plausible. But I think it may take a while (years) and I think once it is possible, it'll take a whole lot of memory and energy -- probably more than could be justified by a child's story use case. "The Diamond Age: Or, A Young Lady's Illustrated Primer" is probably a way's off, unless you're very rich (which I guess was an element even in the novel -- the device just happened to end up in the hands of someone who was poor).
So, given this conjecture, there’s a bunch of hacks I want to work on to try to coax the model into being more consistent without boiling a small lake to do so.
It probably wouldn't be too hard to get Gemini 2.5 flash (the Gemini 2.5 models are really, really good -- much better than older versions) to output structured descriptions of each character -- though I don't know whether or not it would be good at capturing every character, and about updating and persistenting the relevant details across invocations.
So hypothesis 1. is to test getting a {..., dramatisPersonaeWithDescriptions: [...], ...} key in the structured output.
hypothesis 2. is getting access to the allowlisted Imagen APIs for few shot prompting
hypothesis 3 probably isn't practical, but I'm curious whether or not Gemini 2.5 Flash could tell if there were inconsistencies in images between entities, and if so, generate text describing the difference to fix, which could be fed back to a follow on Imagen generation.
hypothesis 4 would be reaching for other Named Entity Recognition machine learning algorithms to process generated text from Gemini 2.5, and then reprompting for detailed descriptions and bios of each generated character, to then try to give more anchoring in the prompts to Imagen.
I find this kind of problem interesting to work on -- there are two ways to view the problem I think -- as a technical/LLM/Foundational Model one -- coaxing the model to "Do the Right Thing", and the alternative is to view it as a human targeted magic trick, and think about the stagecraft and sleight of hand that will hide the fact that the LLM is a savant parrot (this analogy absolutely is right -- the LLM has no structure through which it can recognize something that is correct vs something that it hallucinated).
It's possible in six months Foundational Models will surprise us and this won't be an issue anymore -- but I think that nuanced attention to do this consistency right is sophisticated enough to take time to solve.
Comments
No comments yet. Be the first to comment!